A datahoarder walks into an english class
Ja, ich gebe es zu. In mir steckt ein kleiner /r/DataHoarder. Nein, nicht im großen Stil. Aber doch. Vorallem Unterrichtsmaterial hat es mir angetan. Wenn man den Zugang zu Bildung wieder mal so dermaßen erschwert, regelrecht unsympathisch gestaltet, dass einem fast das Kotzen kommt. Wenn Freiheit nicht frei genug ist, weil man dazu genötigt wird, Inhalte online abzufragen, per Web Browser versteht sich. Immer und immer wieder. Was würde also Aaron Swartz tun?
Jedenfalls habe ich nicht vor, ihm nachzukommen, besagte Inhalte zu teilen und mich somit strafbar zu machen. Auch wenn ich starke Sympathien für seine Person verspüre. An Privatkopien ist aber nichts einzuwenden:
(4) Jede natürliche Person darf von einem Werk einzelne Vervielfältigungsstücke auf anderen als den in Abs. 1 genannten Trägern [Papier oder einem ähnlichen Träger, die jedermann zum eigenen Gebrauch freistehen] zum privaten Gebrauch und weder für unmittelbare noch mittelbare kommerzielle Zwecke herstellen.
Mein Anreiz ist eher meiner Bequemlichkeit geschuldet: Mathe lernen mit Videos, die ich lokal mit nnn und mpv anschauen kann. Wann ich will, wo ich will, so oft ich will.
What’s your telephone number?⌗
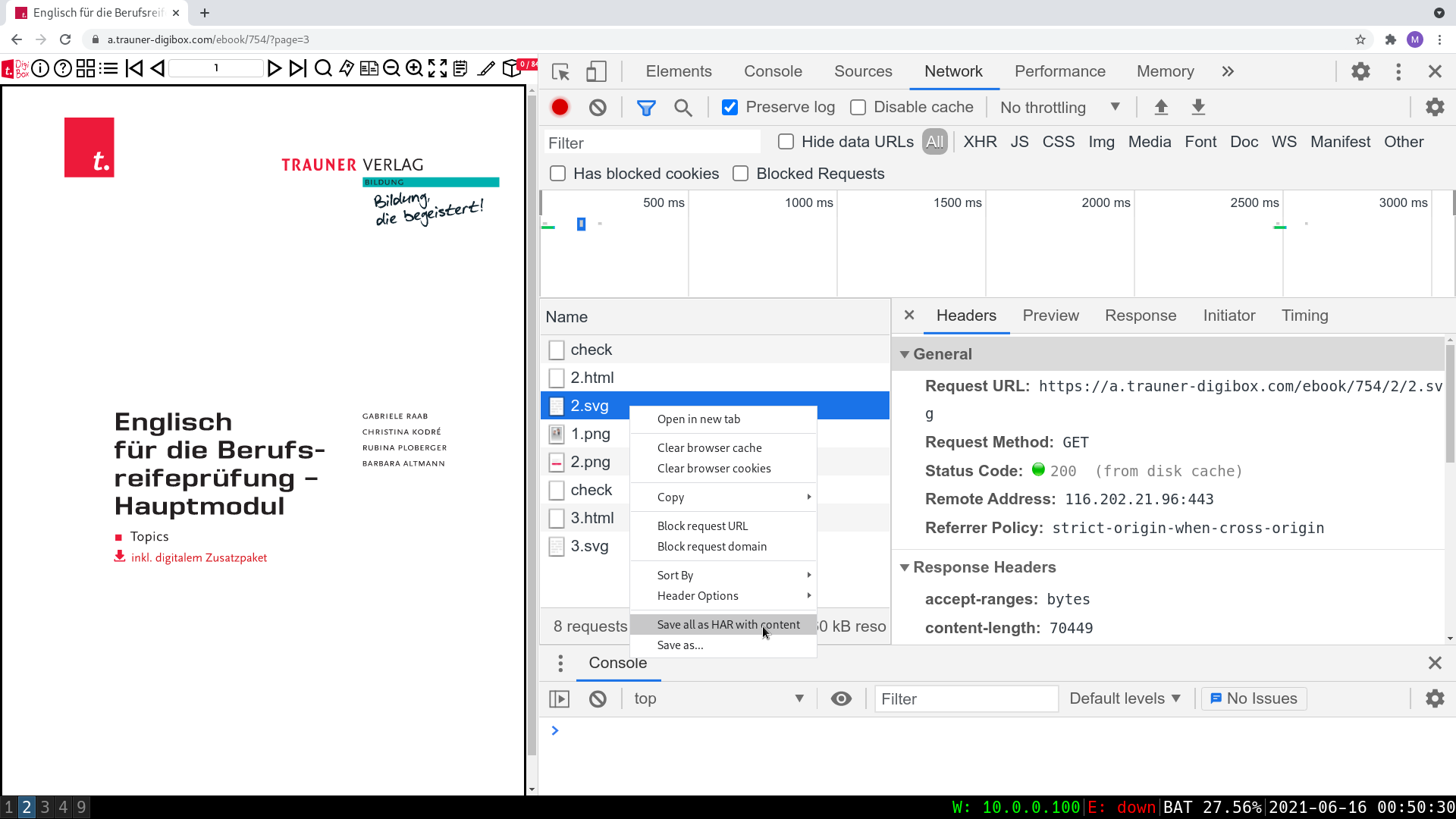
Während ich mir für Mathe mit Python und wget Abhilfe verschaffen konnte, hatte ich mit Englisch schon mehr zu kämpfen um mir von der Trauner Digibox jene Bilder zu sichern, die ich für mein Vorhaben brauche. Ein PDF soll es werden. Nicht mehr, nicht weniger. Nach anfänglichen Versuchen, mein vorheriges Skript einfach abzuändern, verließ mich jedoch das Glück. Just bevor ich aufgeben wollte, kam mir die zündende Idee. Developer Tools -> Network -> Save all as HAR.... Damit lässt sich so ziemlich jeder gemachte Request - oder besser gesagt, getätigte Response - herunterladen. Auf Knopfdruck. Aber wer will schon alle 396 Seiten jenes Buches durchklicken, das einem ohnehin schon soviel Vergnügen bereitet?
while true; do xdotool key Right && sleep 1s; done
Wenige Minuten später, darf man sich an einer 120 MB (!) großen HAR-Datei erfreuen. Nach dem Extrahieren findet man sich vor einer schier unendlichen Anzahl an Dateien wieder, die es erstmal zu sichten gilt. Am Besten gleich den ganzen Unterordner schnappen (in meinem Fall das Buch mit der ID 754) und den Rest löschen. Die einzelnen Seiten bzw. SVG’s sind in Ordner unterteilt, die unter anderem auch mögliche Bilder enthalten, die eingebettet werden.
├── 48
│ ├── 48.svg
│ └── img
│ ├── 1.png
│ ├── 2.png
│ ├── 3.png
│ ├── 4.png
│ ├── 5.png
│ ├── 6.png
│ └── 7.png
├── 49
│ ├── 49.svg
│ └── img
│ ├── 1.png
│ ├── 2.png
│ ├── 3.png
│ └── 4.png
English is a word game⌗
Stackoverflow meinte dann, ich könne mit rsvg-convert und den ganzen Vektorgrafiken ein PDF generieren. Gesagt, getan. Unter Archlinux reichte ein sudo pacman -S librsvg zum Installieren. Ein kleines Shell Skript erledigte dann den Rest:
rsvg-convert -f pdf -o out.pdf $(ls */*.svg | sort -g)
rsvg-convert -f pdf -o "$3.pdf" $(seq -f "./%g/*.svg" $1 $2)
Ganz oder garnit - oder aufgeteilt in einzelne Kapitel.